
GW連休のため自宅に帰ってきてます。じっくり腰を据えてPythonの学習をしようと思ったらPCデスクに置いてあるWindowsパソコン(デスクトップ)が一番快適なので、WindowsパソコンにAnacondaをインストールしてJupyter Labを使えるようにしました。Anacondaはオールインワンな感じで便利です。
ほぼ半日かかった学習(作業)になったので、きちんとした机と椅子に座って作業できるようにしたのは正解だったかなと思っています。
今回のターゲットは、高知県のGoToEat対象店の一覧をCSVで取得することです。
https://www.gotoeat-kochi.com/shop.html
高知県 Go To Eat券対象店リスト(現在はリンク切れしてます)
公式サイトはページ分割されているのでいちいちページを繰って行くのが面倒です。ExcelやGoogleスプレッドシートを使い慣れているとなんかまどろっこしいんですよね。
ただ、スクレイピングは情報提供元のサーバーに負荷をかける場合があるので、なるだけ少ない回数で成功させなくてはなりません。最小限の負荷で一巡させてもらうつもりで解析をしつつPythonスクリプトを作っていきます。
ページネーション(33ページ)が第一の課題
高知県GoToEatの公式サイトは、おそらくスマートフォン等で見るためにページ分割されています。今日現在で1641件のお店が登録されており、ページ数は33ページあります。まずこのページ偏移を検証しなくてはなりません。
今回はJupyter LabにWebサイトの動作検証用に使う「Selenium」を使う事にしました。SeleniumはWebブラウザーをスクリプトで制御することができるので、ページネーションボタンをクリックさせることが出来ます。
逆に言えば「Selenium」を使わずにページ偏移させる方法を知りません。なので今回は絶対に欠かせない機能の一つとなります。
ざっくり考えてみたスクレイピングの動作概要
pythonから「Selenium」を使ってWebブラウザ(Google Chrome)を制御し、1ページ~33ページまで順番に偏移させながら、返ってきたHTMLソースを「BeautySoup」で解析しつつ欲しい情報だけを抽出してCSVファイルにまとめて入手する方法を考えました。
目的とするサイトのページネーションボタンは、1~33ページあるので、リストに1~33の連番を格納して、それを1から順番にfor文で回すことにします。しかし問題はSeleniumにどうやってページネーションボタンを認識させるか?
Seleniumの操作は基本的なことしかやったことないのでリサーチするしかありません。なんとかそれっぽい情報を見つけることが出来ました。
elem_page_btn = browser.find_element_by_link_text(page_number)
elem_page_btn.click()
soup = BeautifulSoup(browser.page_source, features="html.parser")Code language: Python (python)目的のサイトの1ページ目のHTMLソースコードを読むと、<a>タグで挟まれた1というリンクテキストがありました。多分これで行けるんじゃないかな?と考えて実験してみたら「page_number」を1にしたり3にしたりしてもきちんとクリックしてくれます。1つ目の課題をクリアできそうです。
この状態でsoupにBeautifulSoupにそのページのソースを格納して解析し欲しい情報を抜きました。1行に5列の要素が含まれているのでこれらを一つずつ獲得して辞書型配列に取り込みます。それをfor文でループさせて1ページ分全て取り込みます。
つまり、メインのループがページ偏移で、その中に情報を1ページずつ収集する記述が入れ子になる構造です。
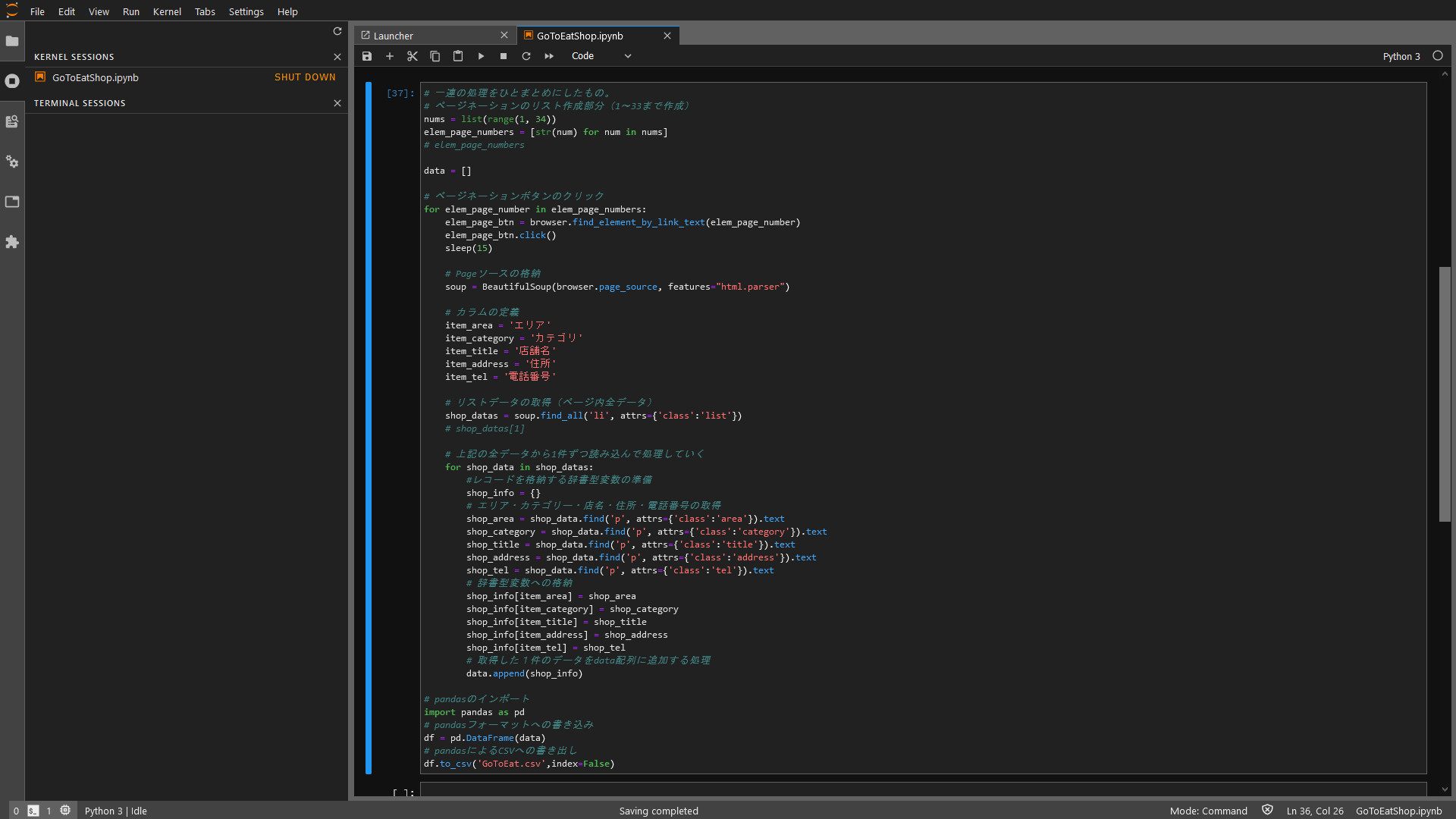
たったこれだけの記述で、33ページを偏移しながらリストを順番に取り込んできてCSVファイルに書き出してくれました。実際のコーディングは、ページ偏移の検証と、1ページのリスト収集を書いたのち、一連の動作を通しで行う様にしたので実際のスクレイピング処理は1発で成功しました。不正アクセス行為とか言われるとまずいのでかなり配慮しました。
タイマー(Sleep)も使用して時間をかけて33ページに渡り自動処理させましたが、Webブラウザー(Google Chrome)が自動で動いている様をコーヒーを飲みながら横目に観察していたのでちょっと気分がいいです。
私レベルの非プログラマーでも作れちゃうって、やっぱりPythonはわかりやすくて凄いなぁ。
CSVファイルで配布してくれてもいいんじゃない?
今日(2021/05/02)時点の高知県のGoToEat対応店のCSVファイルを参考のためにアップしておきます。そもそも情報提供元がCSVファイルでも提供してくれていたらスクレイピングなどする手間は不要なんですけどね。良い教材になったのでよしとするか。
いやぁ本当にPython環境は便利です。Jupyter Labも正直言ってまだまだ使いこなせてないけど徐々に慣れてくると効率がアップするので便利です。プログラミングは頭と手を動かしながら反復練習するしか無いと自分の中では結論づいているのでこういう教材は貴重です。なにしろ興味が沸かないと学習意欲も盛り上がりませんからね。
個人的な主観で言えば、Pythonはやっぱり今一番とっつきやすく結果が得られやすいプログラミング言語(スクリプト言語)だと思います。もちろん用途にもよると思いますが、Webスクレピングはその最たるものだと思います。
なお、先に記したとおりスクレイピングは情報提供元に負荷をかける危険性があるので、安全のためにソースファイルは載せません。もちろんLinux環境やMac環境でもPythonの動作が可能であれば動くと思います。




コメント